ECML–PKDD 2010 Highlights

The city of Barcelona just hosted ECML/PKDD this year and I had the opportunity to go down and check out the latest and greatest mostly from the European machine learning community.
The conference for me started with a good tutorial by Francis Bach and Guillaume Obozinsky. They gave an overview of sparsity: in particular various different methods using l1 regularization to induce sparsity.
The first invited speaker was Hod Lipson from Cornell (and as far as I know one of the few people in our field who has given a TED talk). The main portion of Hod’s talk was about his work on symbolic regression. The idea is the following: consider the following dataset
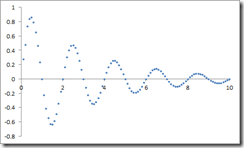
We can apply our favourite regression method, say a spline, to these points and perform accurate interpolation, perhaps even some extrapolation if we chose the right model. The regression function would not give us much insight into why data could be looking like this? In symbolic regression, the idea is that we try to come up with a symbolic formula which interpolates the data. In the picture above, the formula that generated the data was EXP(-x)SIN(PI()x)+RANDBETWEEN(-0.001,0.001) (in Excel). Hod and his graduate students have built a very cool (and free!) app called Eureqa which uses a genetic programming methodology to find a good symbolic expression for a specific dataset. Hod showed us how his software can recover the Hamiltonian and Lagrangian from the measurements of a double pendulum. Absolutely amazing!
Another noteworthy invited speaker was Jurgen Schmidhuber. He tried to convince us that we need to extend the reinforcement learning paradigm. The idea would be that instead of an agent trying to optimize the amount of long term reward he gets from a teacher, he would also try to collect “internal reward”. The internal reward is defined as follows: as the agent learns, he is building a better model of the world. Another way to look at this learning is that the agent just knows how to “compress” better. The reduction in representation he gets from learning from a particular impression is what Jurgen calls the “internal reward”. In other words, it is the difference between the number of bits needed to represent your internal model before and after an impression.
E.g. you listen to a new catchy son: Jurgen says that you think it’s catchy because you’ve never heard anything like this before, it is surprising and hence helps you learn a great deal. This in turn means you’ve just upgraded the “compression algorithm” in your brain and the amount of improvement is now reflected in you experiencing “internal reward”. Listening to a song you’ve heard a million times before doesn’t help compressing at all; hence, no internal reward.
I really like the idea about this internal reward a lot, and as far as I understand it would be very easy to test. Unfortunately, I did not see any convincing experiments so allow me to be sceptical …
The main conference was cool and I’ve met some interesting people working on things like probabilistic logic, a topic I desperately need to learn more about. Gjergji gave a talk about our work on crowdsourcing (more details in a separate post). Some things I marked for looking into are:
- Sebastian Riedel, Limin Yao and Andrew McCallum – “Modeling Relations and Their Mentions Without Labeled Text”: this paper is about how to improve information extraction methods which bootstrap from existing knowledge bases using constraint driven learning techniques.
- Wanner Meert, Nima Taghipour & Hendrik Blockeel – “First Order Bayes Ball”: a paper on how to use the Bayes ball algorithm to figure out which nodes not to ground before running lifted inference.
- Daniel Hernández-Lobato, José Miguel Hernández Lobato, Thibault Helleputte, Pierre Dupont – “Expectation Propagation for Bayesian Multi-task Feature Selection”: a paper on how to run EP for spike and slab models.
- Edith Law, Burr Settles, and Tom Mitchell – “Learning to Tag from Open Vocabulary Labels”: a nice paper on how to deal with tags: they use topic models to do dimensionality reduction on free text tags and then use that in a maximum entropy predictor to tag new music.
I enjoyed most of the industry day as well: I found it quite amusing that the Microsoft folks essentially gave all Bing secrets away in one afternoon: Rakesh Agarwal mentioned the secret sauce behind Bing’s ranker (neural net) whereas Thore Graepel explained the magic behind the advertisements selection mechanism (probit regression). Videos of these talks should be on videolectures.net soon.
One last rant: the proceedings are published by Springer who ask me to pay for the proceedings?!?! I’m still trying to figure out what value they’ve added to our camera-ready we sent them a few months ago …