PQL–A Probabilistic Query Language
At MSR and Bing, when we do machine learning on smaller datasets (say anything below 100GB) we often use relational databases and SQL. Throw in a little bit of Excel and R and you’ve got yourself a very powerful platform for exploratory data analysis.
After the exploratory phase, we often build statistical models (adPredictor, TrueSkill, Matchbox, …) to discover more complex structures in the data. Infer.NET helps us prototype these graphical models, but unfortunately it forces you to work in a mode where you first create a binary that performs inference, suck out all data to your machine, run inference locally and then write all inference results back to the DB. My local machine is way slower than the machines which run our DB or our local compute cluster so ideally I’d like to have a platform which computes “close” to the data.
The Probabilistic Query Language (or PQL) is a language/tool which I designed two years ago, during an internship with Ralf Herbrich and Thore Graepel, where we had the following goals in mind:
- Allow for rapid prototyping of graphical models in a relational environment
- The focus should be on specifying models, not algorithms
- It should enable large scale execution and bring the computation to the data, rather than the data to the computation Using SQL Server, DryadLinq (Map-Reduce for .NET) and Infer.Net I built a prototype of PQL and tested it on some frequently used models at Microsoft. In this post I want to introduce the PQL language and give a few examples of graphical models in PQL. Let’s start with a very simple example where we have a DB with a table containing people’s info and a table with records describing doctor visits for those people. Assume the following relational schema
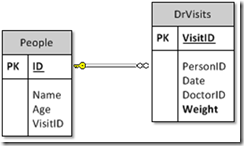
We assume that people have an unknown weight and when they go to the doctor, she measures this weight. Depending on the time of day (after a heavy lunch), this estimate could be off a bit. A statistical model to capture these assumption is to introduce a random variable for the weight for each person in the People table, put a prior on this variable and connect it with the observations in the DrVisits table. So how do we write such a model in PQL?
PQL is very much like SQL but with two extra keywords: AUGMENT and FACTOR. AUGMENT allows us to add random variables to the DB schema. In the example above we would write
People = AUGMENT DB.People ADD weight FLOATThis essentially defines a “plate” in graphical model speak: for each row in the People table, a random variable over the real numbers called weight is defined.
The FACTOR keyword in PQL allows to introduce factors between random variables as well as any other variables in the DB schema. FACTOR follows the relational SQL syntax to specify exactly how to connect variables. To specify a normal prior on the weight variable we could write
FACTOR Normal(p.weight | 75.0,25.0) FROM People pThis introduces a normal factor for each row in the People table (the FROM People p part). The final component of our program connects the random variable with observations. In this case, we use the familiar SQL JOIN syntax to specify how to connect rows from the People table to the rows in the DrVisits table. In PQL we write
FACTOR Normal(v.weight | p.weight, 1.0)
FROM People p
JOIN DrVisit v ON p.id = v.personidExcept for the first line this is exactly SQL; instead of doing a query, the FACTOR statement describes the “probabilistic augmentation” of the DB schema”.
For the example above, this is it, the PQL program contains five lines of code and can be sent to the DB. It will run inference by performing EP or variational Bayesian inference. The inference itself can be run either within the database (this was implemented by Tina Palla who was an intern with us) or on the DryadLinq cluster.
Another example of PQL is the program to describe the TrueSkill ranking system. In this example we assume two-player games stored using a table of players (called Players) and a table of game outcomes (called PlayerGames). Each game played generates two rows in the PlayerGames table: one for the winner and the loser (with a score) column specifying who is the winner and who is the loser. The PQL program for TrueSkill is written below
Players = AUGMENT DB.Players ADD skill FLOAT;
PlayerGames = AUGMENT DB.PlayerGames ADD performance FLOAT;
FACTOR Normal(p.skill | 25.0, 20.0) FROM Players p;
FACTOR Normal(pg.performance | p.skill, 0.1)
FROM PlayerGames pg
JOIN Players p ON pg.player_id = p.player_id;
FACTOR IsGreater(pgb.performance, pga.performance)
FROM PlayerGames pga
JOIN PlayerGames pgb ON pga.game_id = pgb.game_id
WHERE pga.player_id < pgb.player_id AND pga.score = 0;
FACTOR IsGreater(pga.performance, pgb.performance)
FROM PlayerGames pga
JOIN PlayerGames pgb ON pga.game_id = pgb.game_id
WHERE pga.player_id < pgb.player_id AND pga.score = 2;There are a lot of features in PQL I haven’t covered in this blog post (like using random variables in a WHERE clause to create mixture models) but I wanted to give you a flavour of what we’ve been working on so far.
While working on PQL I learned a lot about the state of the art in probabilistic databases and statistical relational learning. I think compared to this academic work, PQL does not add many theoretical contributions; our goal is to design a tool which takes statistical relational learning out of the laboratory into the hands of data mining practicioners.