Inference in Infinite Capacity Models
Through the work we’ve done on nonparametric Bayesian (NPBayes) time series models, I’ve been thinking a lot about how we can improve inference in infinite capacity models. One observation is that we don’t want to throw away all the knowledge and experience we’ve built up in doing deterministic inference for finite models.
Expectation propagation (EP), belief propagation (BP) and variational Bayes (VB) are three deterministic inference techniques which have proven to be useful in many different scenarios. People have tried to apply these to NPBayes with mixed success:
- Minka & Ghahramani applied EP to do inference in DP mixtures; as far as I understand their work, their are a few annoyances: a) the approximation can depend heavily on the order in which one processes the data points; b) the posterior distribution ends up having a cluster centre for each data point and these centres don’t necessarily (and it their experiments never) fall on top of each other. This is weird as the whole point of the DP is to make sure that there is only a small number of cluster centres. I can imagine there are other ways to apply EP to DP mixtures but so far this endeavour hasn’t drastically changed the business of inference for NPBayes.
- There have been a few approaches (Blei, Kurihara, …) to apply VB to DP mixtures and related models. The inference is quite elegant and quite a few applications have shows that VB inference is competitive with Gibbs sampling. VB has advantages such as returning a lower bound on the marginal likelihood which are hard to get using sampling methods. As far as I am concerned, the disadvantage of VB is that the math can become a bit hairy.
- I am not aware of any BP inference for NPBayes. I’d love to hear if anyone has tried this?
What I’ve been thinking about lately is something completely different. Our work on the beam sampler has shown that if one uses a slice sampler in the appropriate way, one can adaptively slice up an infinite model into a finite model and use deterministic inference methods on a finite graphical model. The beam sampler is essentially a combination of this slice sampling idea with belief propagation (more in particular, the forward-backward algorithm). The scope of this technique is broader than the iHMM though: we applied this technique to the iFHMM and one can also imagine this scheme to work on infinite state Bayesian networks (ISBN). In the ISBN context we would introduce a slice for every infinite dimensional distribution and switch between sampling the slice variables and deterministic inference in the finite Bayesian network. The disadvantage of the slice sampler is that one ends up with samples and for many applications it is not clear how to combine them.
After a suggestion by Radford Neal I also looked into a different scheme to adaptively truncate the iHMM. The algorithm is an adaptation of the embedded HMM sampling scheme for nonlinear dynamical systems. Imagine we draw the trellis for the infinite dimensional state space of an iHMM:
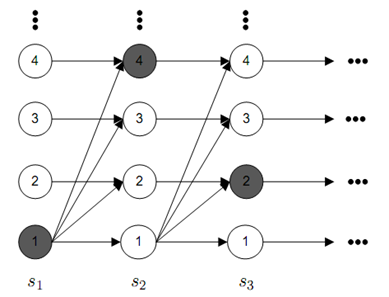
The horizontal … denote that there are T time steps in the iHMM, the vertical … denote that there are a possible infinite number of state the iHMM can be in. The grayed out nodes denote a initial state sequence assignment (we are going to sample here). Note that I haven’t draw all the possible transition arrows, in general there is a nonzero transition from every node at time t-1 to time t.
The embedded HMM sampler works as follows: for each time step, we create a pool of states which we want to include in the deterministic inference which we will run later. In the image below, I denote the states in the pool by shading them with light gray. The size of this pool will be a parameter which we can choose later (in the picture below it is 2).
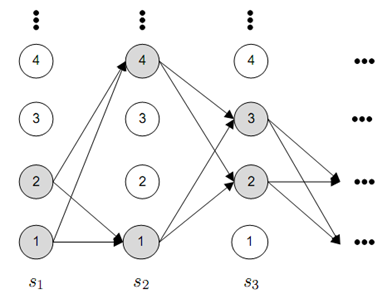
We can choose how to draw the pools but one must make sure that the states from the previous sample (see picture above) are certainly included in the pool; it is also desirable to not spend too much computation on selecting the pool of states. One iteration of a sampler consists of sampling the pool states and then running the forward-filtering backward-sampling algorithm in a finite graphical model that only uses pool states. If you go through the math you will find that you’ll have to slightly modify the dynamic program to make this work. I will post a short technical report with some mathematical details on my web page soon.
The embedded HMM sampler shares many of the properties of the slice sampler but differs in one major respect: with the slice sampler one has little control over how much computation one will spend on one iteration. The reason is that between iterations the size of the finite model we consider grows or shrinks according to the sampled slice variables. In the embedded HMM however, we explicitly control the size of the finite model we want to do inference over. The flip side is that if we choose the pools in the embedded HMM sampler to be small we will likely increase the mixing time of the sampler.
Nonetheless the basic idea is the same as for the beam sampler: you choose a finite subset of the NPBayes graphical model and then run any deterministic inference algorithm that will get you a sample form the finite subset.
The message I want to get across here is that if we want to do inference in infinite capacity models while at the same time leveraging a powerful deterministic inference algorithm for finite models we can do so by combining a method that truncates the infinite model (say using slice sampling or the embedded HMM sampler) and then applying the deterministic inference scheme on a finite graphical model. I am eager to play around with Infer.NET and see if it will be possible to do use this idea to automatically generate inference algorithms for infinite capacity models.