Dirichlet Distributions and Entropy
In between all the Netflix excitement I managed to read a paper that was mentioned by David Blei during his machine learning summer school talk: Entropy and Inference, Revisited by Ilya Nemenman, Fariel Shafee and William Bialek from NIPS 2002. This paper discusses some issues that arise when learning Dirichlet distributions. Since Dirichlet distributions are so common, I think these results should be more widely known.
Given that I’ve been reading a lot of natural language processing papers where Dirichlet distributions are quite common, I’m surprised I haven’t run into this work before.
First a little bit of introduction on Dirichlet distributions. The Dirichlet distribution is a “distribution over distribution”; in other words: a draw from a Dirichlet distribution is a vector of positive real numbers that sum up to one. The Dirichlet distribution is parameterized by a vector of positive real numbers which captures the mean and variance of the Dirichlet distribution. It is often very natural to work with a slightly constrained Dirichlet distribution called the symmetric Dirichlet distribution: in this case the vector of parameters to the Dirichlet are all the same number. This implies that the mean of the Dirichlet is a uniform distribution and the variance is captured by the magnitude for the vector of parameters. Let us denote with beta the parameter of the symmetric Dirichlet. Then, when \beta is small, samples from the Dirichlet will have high variance while with beta large, samples from the Dirichlet will have small variance. The plot below illustrates this idea for a Dirichlet with 1000 dimensions: the top plot has very small beta and hence a draw from this Dirichlet has only a few nonzero entries (hence high variance) while the Dirichlet with beta = 1, all entries of the sample have roughly the same magnitude (about 0.001).
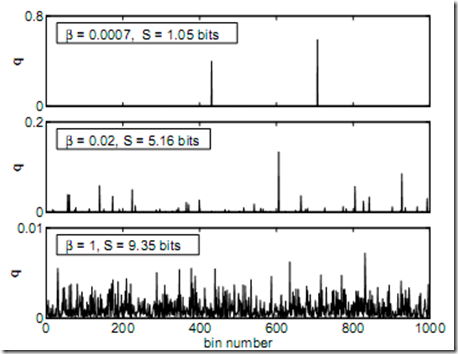
Another way to approach the effect of beta is to look at the entropy of a sample from the Dirichlet distribution, denoted by S in the images below. The entropy of a Dirichlet draw is high when beta is large. More in particular, it is upper bounded by ln(D) where D is the dimensionality of the Dirichlet when beta approaches infinity and the Dirichlet distribution will approach a singular distribution at completely uniform discrete distribution. When beta approaches 0, a draw from a Dirichlet distribution approaches a delta peak on a random entry which is a distribution with entropy 1. The key problem the authors want to address is that when learning an unknown distribution, if we use a Dirichlet prior, beta pretty much fixes the allowed shapes while we might not have a good reason a priori to believe that what we want to learn is going to look like either one of these distributions.
The way the authors try to give insight into this problem is by computing the entropy of a random draw of a Dirichlet distribution. In equations, if we denote with S the entropy, it will be a random variable with distribution
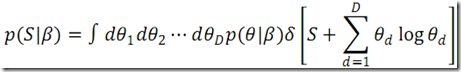
Computing the full distribution is hard but the authors give a method to compute its mean and variance. The following picture shows the mean and variance of the entropy for draws of a Dirichlet distributions. A bit of notation: K is the dimensionality of the Dirichlet distribution, Xi is the mean entropy (as a function of beta) and sigma is the variance of the entropy as a function of beta.
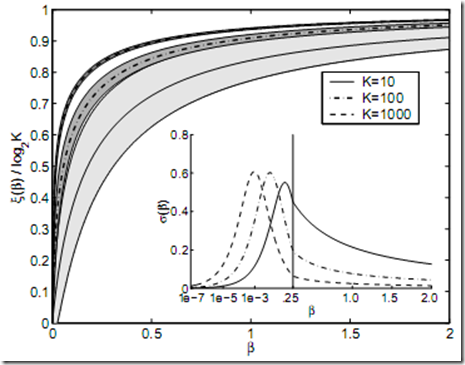
As you can see from this plot, the entropy of Dirichlet draws is extremely peaked for even moderately large K. The authors give a detailed analysis of what this implies but the main take-away message is this: as you change beta, the entropy of the implied Dirichlet draws varies smoothly, however, because the variance of the entropy is very peaked, the a priori choice of beta almost completely fixes the entropy.
This is problematic as it means that unless our distribution is sampled almost completely, the estimate of the entropy is dominated by the choice of our prior beta. So how can we fix this? The authors suggest a scheme which I don’t completely understand but boils down to a mixture of Dirichlet distributions by specifying a prior distribution on beta as well.
This mixture idea ties in with something we did in our EMNLP 09 paper: when we were training our part-of-speech tagger we had to choose a prior for the distribution which specifies what words are generated for a particular part-of-speech tag. We know that we have part-of-speech tag classes that generate very few words (e.g. determiners, attributes, …) and a few classes that generate a lot of words (e.g. nouns, adjectives, …). At first, we chose a simple Dirichlet distribution (with fixed beta) as our prior and although the results were reasonable, we did run into the effect explained above: if we set beta to be large, we got very few states in the iHMM where each state outputs a lot of words. This is good to capture nouns and verbs but not good for other classes. Conversely, when we chose a small beta we got a lot of states in the iHMM each generating only a few words. Our next idea was to put a Gamma prior on beta; this helped a bit, but still assumed that there is only one value of beta (or one type of entropy distribution) which we want to learn. This is again unreasonable in the context of natural language. Finally, we chose to put a Dirichlet process prior on beta (with a Gamma base measure). This essentially allows different states in the iHMM to have different beta’s (but we only expect to see a few discrete beta’s).
Entropy and Inference, Revisited is one of those papers with a lot of intuitive explanations; hopefully it helps you make the right choice for priors in your next paper as well.